
Download: [download id=’17826′]
EINFÜHRUNG
In den meisten Fällen geht es bei statistischen Datenanalysen darum, gewisse unbekannte Kenngrößen einer Population (auch Grundgesamtheit genannt) zu bestimmen. In der Statistik nennt man dies Schätzen oder Fitten unbekannter Parameter. Beispiele sind etwa Wahrscheinlichkeiten, Mittelwerte, Mediane, Standardabweichungen, Korrelationen oder auch Parameter von Regressionsmodellen. Da die Ergebnisse einer Schätzung auf einer repräsentativen Stichprobe basieren, unterliegen die Schätzungen der unbekannten Kenngröße der zufälligen Schwankung. D. h.: Würde die Studie mit einer neuen repräsentativen Stichprobe wiederholt, so könnte man davon ausgehen, dass die neuen Schätzungen mehr oder weniger stark von den ersten Schätzungen abweichen. Auch muss man annehmen, dass die Schätzung nicht exakt dem unbekannten Wert des Parameters für die Population entspricht. Es ist daher wichtig einzuschätzen, wie genau der unbekannte Wert der gesuchten Kenngröße geschätzt wurde. Ein wichtiges Werkzeug hierfür sind die so genannten Konfidenzintervalle, die von Neyman bereits 1937 eingeführt wurden [1]. Ein Konfidenzintervall ist demnach ein wichtiges Hilfsmittel, um die Ungenauigkeit von Schätzungen unbekannter Parameter in der Statistik zu veranschaulichen.
Unter einem Konfidenzintervall (confidence interval = CI) versteht man ein Intervall, welches auf Basis einer gegebenen Stichprobe berechnet wird und den wahren unbekannten Wert des Parameters mit einer vorgegebenen Wahrscheinlichkeit 1-α überdeckt (= Überdeckungswahrscheinlichkeit), siehe auch Abbildung 1.

Für α werden hierbei sinnvollerweise kleine Werte gewählt, meistens 5 %, womit sich in diesem Fall ein 95 %-CI (CI95) ergibt. Dabei ist zu beachten, dass ein CI umso länger wird, je kleiner α gewählt wird. Generell ist es das Ziel, die Grenzen so zu wählen, dass die Überdeckungswahrscheinlichkeit genau 1-α ist. In diesem Fall spricht man auch von einem exakten CI.
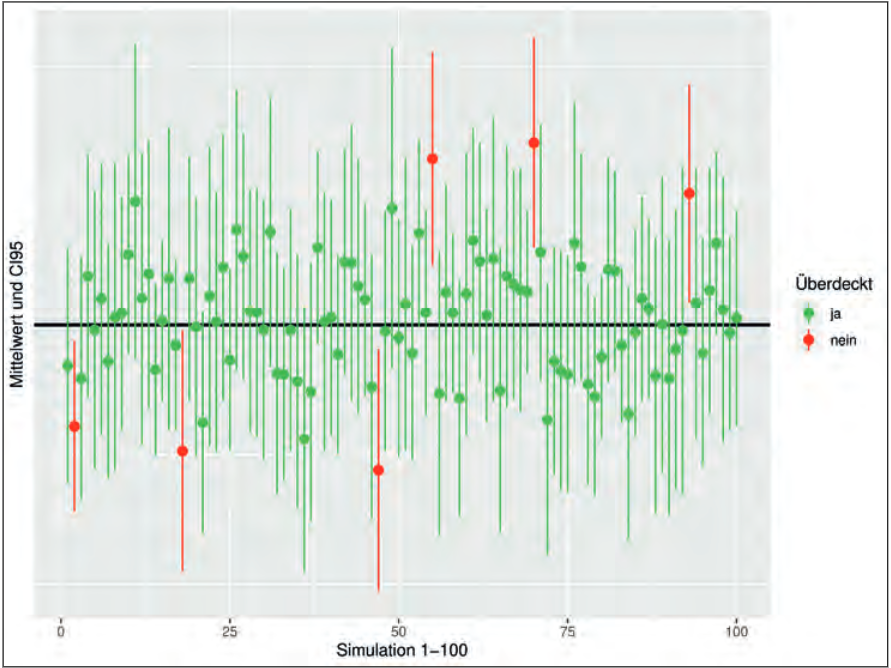
Es ist sehr wichtig, den für die Definition des CI zentralen Begriff der Überdeckungswahrscheinlichkeit richtig zu interpretieren. Eine Überdeckungswahrscheinlichkeit von 1-α bedeutet, dass in (mindestens) (1-α) % der Fälle, in denen wir auf Basis einer Stichprobe ein CI berechnen, dieses Intervall tatsächlich den wahren unbekannten Wert des Parameters enthält. Es ist folglich nicht richtig, dass der wahre Wert des Parameters mit (mindestens) (1-α) % Wahrscheinlichkeit im berechneten CI liegt. Denn nachdem das CI auf Basis der vorliegenden Daten berechnet wurde, liegt der gesuchte unbekannte Wert des Parameters entweder im Intervall oder eben nicht. Die Wahrscheinlichkeit, dass der unbekannte Wert des Parameters im berechneten CI liegt, ist demnach nicht 1-α, sondern eben 1 oder 0. Diese häufige und fundamentale Fehlinterpretation des CI bezeichnen Morey et al. als „The Fundamental Confidence Fallacy“ [2]. In Abbildung 2 findet sich ein Beispiel hierfür. Es wurden 100 normalverteilte Zufallsstichproben mit jeweils 20 Beobachtungen erzeugt und anschließend für jede Stichprobe jeweils der Mittelwert (arithmetisches Mittel) und das CI95 für den Mittelwert berechnet. Es wäre demnach zu erwarten (Erwartungswert), dass in 95 Fällen die CIs den wahren unbekannten Mittelwert der Normalverteilung überdecken. Tatsächlich kommen wir mit der Simulation dem erwarteten Wert sehr nahe und erhalten in 94 Fällen eine Überdeckung.
Bei der unteren und oberen Grenze des CI handelt es sich um Schätzungen, weshalb jede neue Stichprobe zu einer jeweils mehr oder weniger anderen unteren und oberen Grenze führt (Abb. 2). Es ist auch möglich, einseitige CIs zu betrachten, bei denen dann eben nur die untere oder obere Grenze geschätzt werden muss, während die jeweils andere Grenze auf den maximal bzw. minimal möglichen Wert des jeweiligen Parameters gesetzt wird. Ist der Parameter θ, der geschätzt werden soll, zum Beispiel eine Wahrscheinlichkeit (Minimum = 0, Maximum = 1), so ergäben sich die folgenden einseitigen (1-α)- Konfidenzintervalle CI = [0, So] bzw. CI = [Su, 1].
Die Berechnung von CIs, speziell exakten CIs, ist in der Praxis in vielen Fällen sehr schwierig bzw. sogar unmöglich, weshalb man stattdessen oft auf approximative CIs zurückgreifen muss. In der klassischen Statistik werden solche genäherten CIs mit Hilfe asymptotischer (n wächst ins Unendliche) Ergebnisse berechnet. Das wichtigste Hilfsmittel dafür sind sogenannte zentrale Grenzwertsätze, welche auf eine Normalverteilung als Grenzwertverteilung für den Schätzer führen. In diesem Fall gilt in Gleichung (2) aus Abbildung 1: k1 = k2 = z1-α/2, wobei z1-α/2 das (1-α/2)-Quantil der Normalverteilung mit Mittelwert 0 und Standardabweichung 1 ist. Im Fall α = 5 % ergibt sich z0,975 = 1,96 ≈ 2 (vgl. Abschnitt 6.5 in [5]).
In der modernen datengestützten Statistik kommen für die Berechnung angenäherter (approximativer) Konfidenzintervalle sogenannte Permutations- oder Resamplingverfahren und im speziellen das sogenannte Bootstrapping [6] zum Einsatz (nähere Informationen zum Thema Bootstrap-Konfidenzintervall sind im Supplement über den nebenstehenden QR-Code zu finden). Im Unterschied zur klassischen Statistik sind bei diesen Verfahren weniger (theoretische) Annahmen nötig. So kann ein entsprechendes CI auch ohne ein konkretes Wahrscheinlichkeitsmodell und ohne Berechnung des Standardfehlers ermittelt werden. Alle benötigten Informationen werden direkt aus den Daten gewonnen. Im einfachsten Fall wird beim Bootstrapping aus der vorliegenden repräsentativen Stichprobe durch Ziehen mit Zurücklegen eine neue Zufallsstichprobe identischer Größe erzeugt und der gesuchte Parameter auf Basis dieser neuen Zufallsstichprobe geschätzt. Dieses Vorgehen wird dann tausende Male wiederholt, woraus sich entsprechend tausende Schätzwerte für den gesuchten Parameter ergeben. Die einfachste Möglichkeit zur Berechnung des Boostrap-CI besteht darin, das α/2- und (1-α/2)-Quantil dieser Schätzwerte als Unter- und Obergrenze des Intervalls zu nehmen. Das Bootstrapping funktioniert erfahrungsgemäß auch bei kleinen Stichprobengrößen sehr gut, wobei Bootstrap-CIs für kleine bis moderate Fallzahlen (10 ≤ n ≤ 50) und schiefe Verteilungen tendenziell etwas zu kurz sind (vgl. Kapitel 3 in [7]).
Der generelle Nachteil der approximativen CIs liegt darin, dass die genaue Überdeckungswahrscheinlichkeit unbekannt ist. Insbesondere ist auch nicht klar, ob diese, wie in der Definition des CIs gefordert, größer oder gleich 1-α ist. Es ist bekannt, dass approximative CIs für kleine bis moderate Fallzahlen (n ≤ 50) tendenziell zu kurz sind und nicht die vorgegebene Überdeckungswahrscheinlichkeit von 1-α erreichen. Jedoch ist dies auch bei den theoretisch exakten CIs nicht garantiert, da nicht klar ist, ob die für die Herleitung notwendigen (theoretischen) Annahmen in der Praxis auch tatsächlich erfüllt sind. Entsprechend ist es in jedem Fall nötig, CIs, wie jedes statistische Resultat, mit gebührender Vorsicht zu interpretieren. Bei größeren Fallzahlen (n ≥ 100) sind die Unterschiede zwischen den verschiedenen Ansätzen hingegen üblicherweise klein bis sehr klein und auffällige Unterschiede können darauf hindeuten, dass gemachte Annahmen nicht zutreffend sind. Insbesondere sollte in diesem Fall hinterfragt werden, ob das statistische Model richtig gewählt wurde. CIs sind auch eng mit statistischen Hypothesentests verwandt, wobei es einige Argumente dafür gibt, warum CIs den statistischen Tests vorzuziehen sind [8,9]. Darauf wollen wir hier aber nicht näher eingehen, sondern betrachten zwei Beispiele, wobei wir im ersten Beispiel zeigen, wie ein CI für die Fallzahlplanung herangezogen werden kann.
BEISPIEL 1: VENÖSE SAUERSTOFFSÄTTIGUNG AN DER EKZ
Wir gehen davon aus, dass die vorliegenden Daten zur venösen Sauerstoffsättigung (SvO2) von 30 Patienten einer Normalverteilung unterliegen, wobei wir am Mittelwert der Verteilung interessiert sind und die Standardabweichung unbekannt ist. Die Formeln für das exakte und asymptotische CI für den Mittelwert finden sich in Abbildung 3. In Abbildung 4 sehen wir das exakte, das asymptotische und das Bootstrap-CI auf Basis von 10.000 Wiederholungen.

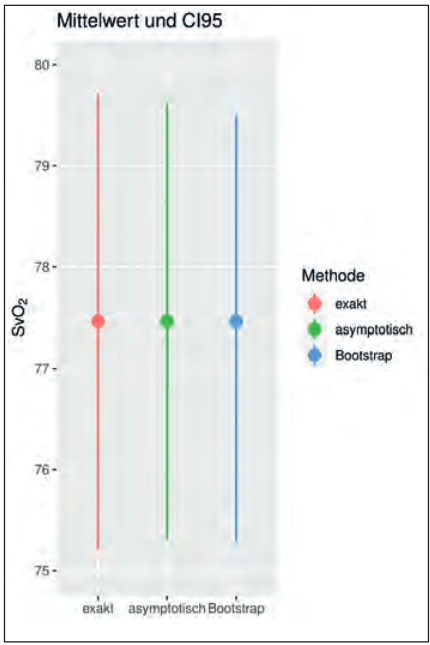
Da z0,975 = 1,96 < 2,05 = t29;0,975, ist das asymptotische CI etwas kürzer als das exakte CI. Das Boostrap-CI ist am kürzesten und zudem leicht asymmetrisch. Auf Basis der vorliegenden Daten erscheint demnach eine mittlere venöse Sauerstoffsättigung im Bereich von 75–80 % für das beobachtete EKZ-Patientenkollektiv plausibel.
FALLZAHLBERECHNUNG MITTELS CI
Hierfür betrachten wir nun die obigen Daten als Daten einer Pilotstudie, deren Ergebnisse wir für die Fallzahlplanung einer neuen, größer angelegten Studie nutzen wollen. Der mittlere SvO2 lag in der Studie bei 77,5 %, die Standardabweichung bei 6,0 %. Für die Fallzahlberechnung müssen wir außerdem α und die Länge des CI festlegen. Wir wählen α = 5 % und eine Länge des CI95 von 3 % (Mittelwert +/-1,5 %). Da die Nullstelle für die Funktion f aus Gleichung (7) zwischen n = 63 und n = 64 liegt, ist die benötigte Fallzahl für die geplante Studie n = 64. Bei der Anwendung der asymptotischen Formel aus Gleichung (9), ergibt sich eine Fallzahl von n = 62. Das etwas kürzere asymptotische CI führt demnach zu einer leichten Unterschätzung der Fallzahl (Abb. 5).

BEISPIEL 2: URINMENGE AN DER EKZ
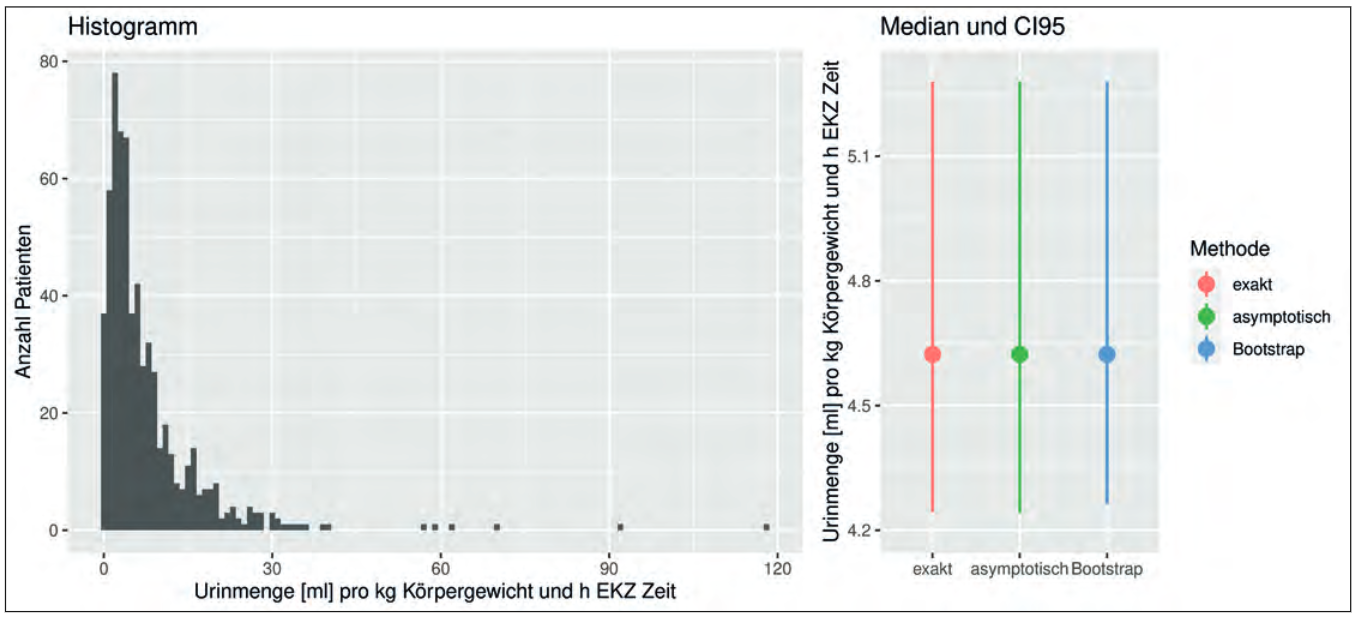
Wir untersuchen die ausgeschiedene Urinmenge in ml pro kg Körpergewicht und h EKZ-Zeit anhand der Daten von 627 Patienten [11]. Aufgrund der schiefen Verteilung der Daten (vgl. Histogramm in Abb. 6), wählen wir den Median, um die Lage der Daten zu beschreiben. Der Median und die CI95s für den Median sind in Abbildung 6 dargestellt. Wir sehen, dass die CIs für alle drei Methoden sehr ähnlich sind, was wegen der recht hohen Fallzahl nicht überrascht. Genauer gesagt sind die oberen Grenzen der Intervalle in allen drei Fällen identisch bei 5,28 ml. Die unteren Grenzen liegen bei 4,243 ml (exakt), 4,242 ml (asymptotisch) und 4,263 ml (Bootstrap) und unterscheiden sich somit nur minimal. Wir können demnach auf Basis der vorliegenden Daten davon ausgehen, dass die ausgeschiedene Urinmenge für die vorliegende Patientenpopulation im Median zwischen 4,2 und 5,3 ml pro kg Körpergewicht und h EKZ-Zeit liegt.
ZUSAMMENFASSUNG
Konfidenzintervalle sind heute ein unverzichtbares Hilfsmittel der angewandten Statistik, um die Unsicherheit in der Schätzung von unbekannten Parametern auszudrücken, und können mittels moderner Statistiksoftware für beliebige Parameter (Wahrscheinlichkeiten, Mittelwerte, Mediane, Standardabweichungen, Korrelationen, Parameter von Regressionsmodellen etc.) berechnet werden. Ihre Verwendung wird in den aktuellen Empfehlungen zur Berichterstattung von Studienergebnissen empfohlen (vgl. etwa CONSORT 2010 [12] bzw. https://www.equator-network.org/). Insbesondere die modernen datenbasierten Ansätze wie etwa Bootstrap-Konfidenzintervalle, welche weniger (theoretische) Annahmen als exakte oder asymptotische Intervalle benötigen, sollten vermehrt eingesetzt werden.







