Fazitbox
Pro und Contra diagnostische Plots für die lineare Regression:
Pro
- Diagnostische Plots eignen sich sehr gut dazu, um die Voraussetzungen für die lineare Regression zu prüfen. Man spricht in diesem Zusammenhang auch von Residuendiagnostik, da die meisten Plots auf den Residuen des berechneten linearen Modells basieren.
- Durch die zusätzliche Verwendung von nichtparametrischen Kurvenanpassungen lassen sich auffällige Strukturen in den diagnostischen Plots besser erkennen und beurteilen.
Contra
- Es ist Erfahrung im Umgang mit diagnostischen Plots erforderlich, um auffällige Abweichungen zu erkennen. Gerade bei kleinen bis moderaten Fallzahlen ist es generell schwierig, eine zuverlässige Aussage zu treffen.
Einführung
Lineare Modelle zählen zu den am häufigsten verwendeten Modellen in der Statistik. Wie alle Modelle stellen auch sie nur eine Annäherung an die Realität dar. Die Gültigkeit der gewonnenen Ergebnisse hängt außerdem davon ab, ob die getroffenen Modellannahmen erfüllt sind [1]. In diesem Tutorial werden wir eine Reihe von diagnostischen Plots besprechen, die sich zur Überprüfung dieser Modellannahmen eignen. Die meisten dieser Plots basieren auf den sogenannten Residuen [1]. Man spricht deshalb auch von Residuendiagnostik. Es können auch verschiedene statistische Signifikanztests für diesen Zweck verwendet werden. Darauf werden wir im Rahmen dieses Tutoriums aber nicht näher eingehen. Zur Veranschaulichung der Plots werden wir verschiedene Szenarien verwenden und diese auf lineare Modelle von realen Daten anwenden.
Residuen versus gefittete Werte
Wir beginnen mit dem zentralen Plot für die Residuendiagnostik, bei dem die Residuen gegen die gefitteten Werte aufgetragen werden. Dieser Plot ist auch als Tukey-Anscombe-Plot bekannt. Wenn wir davon ausgehen, dass die Voraussetzungen für das lineare Modell erfüllt sind, sollten die Residuen in diesem Fall zufällig um den Wert 0 herum schwanken. Insbesondere sollten keine Strukturen, Kurvenverläufe oder Trends erkennbar sein. Schwanken die Residuen jedoch um einen anderen Wert, ist dies ein Zeichen dafür, dass der Erwartungswert des Zufallsfehlers nicht gleich 0 ist (vgl. Voraussetzung (3) in [1]). Eine kegelförmige Struktur weist auf eine Heteroskedastizität der Residuen hin, was einer Abweichung von der angenommenen Homoskedastizität (vgl. Voraussetzungen (1) und (3) in [1]) entspricht. Kurvenverläufe entstehen, wenn das Modell unvollständig ist und noch nicht alle Informationen, die in den Daten enthalten sind, erfasst wurden. Dies kann beispielsweise bedeuten, dass noch eine wichtige Variablen fehlt oder dass zusätzlich noch ein weiterer Term mit einer Transformation einer bereits enthaltenen Variablen aufgenommen werden müsste (vgl. Voraussetzung (0) in [1]). Zeigt sich ein Trend, kann dies ein Hinweis dafür sein, dass die Residuen nicht (stochastisch) unabhängig sind (vgl. Voraussetzung (2) in [1]). Wir werden die angesprochenen Abweichungen im Folgenden unter Verwendung verschiedener Szenarien veranschaulichen. Dabei erzeugen wir jeweils zwei Varianten der Tukey-Anscombe-Plots. Im ersten Fall erzeugen wir die Plots auf Basis von 500 Beobachtungen, um die Effekte deutlich sichtbar zu machen. Im zweiten Fall, der das identische Szenario zeigt, verwenden wir „nur“ 30 Beobachtungen. Letzteres entspricht einer Situation, wie sie häufig bei praktischen Anwendungen vorzufinden ist. Dies soll verdeutlichen, wie schwierig es in diesem Fall ist, die entsprechende Abweichung sicher zu erkennen.
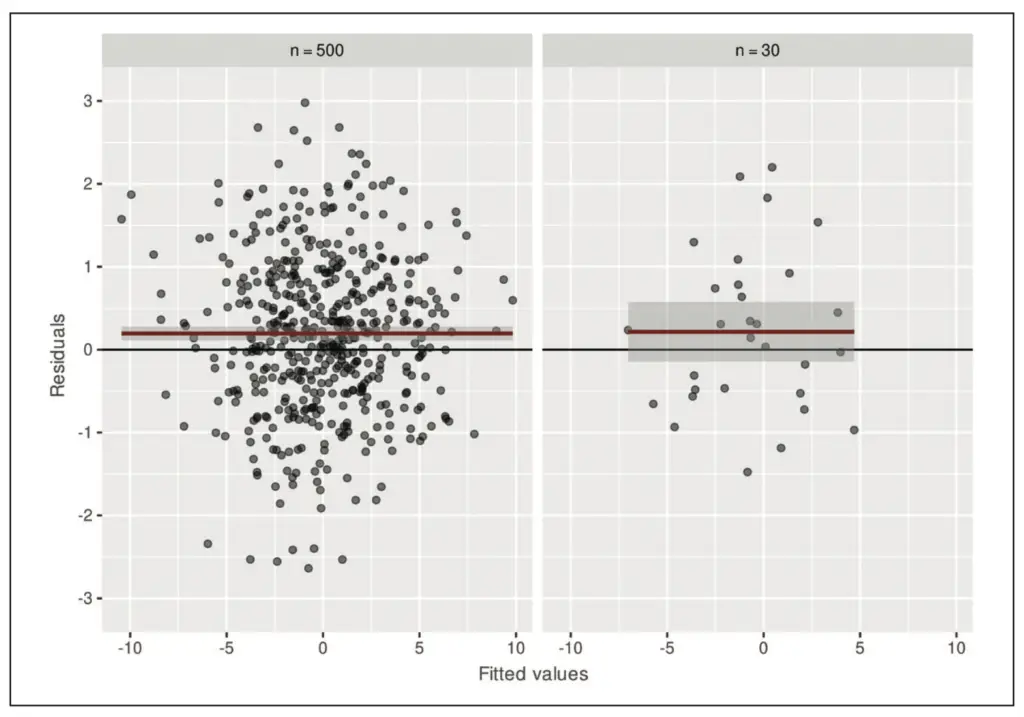
In Abbildung 1 sehen wir, dass die Residuen nicht um den Wert 0 herum schwanken. Alle anderen Voraussetzungen für das lineare Modell sind erfüllt. Dieses Problem lässt sich relativ einfach beheben, indem ein konstanter Term (Achsenabschnitt) in das Modell aufgenommen wird. Da es generell üblich ist, dass das lineare Modell einen konstanten Term enthält, tritt diese Situation in der Praxis aber nur sehr selten auf.
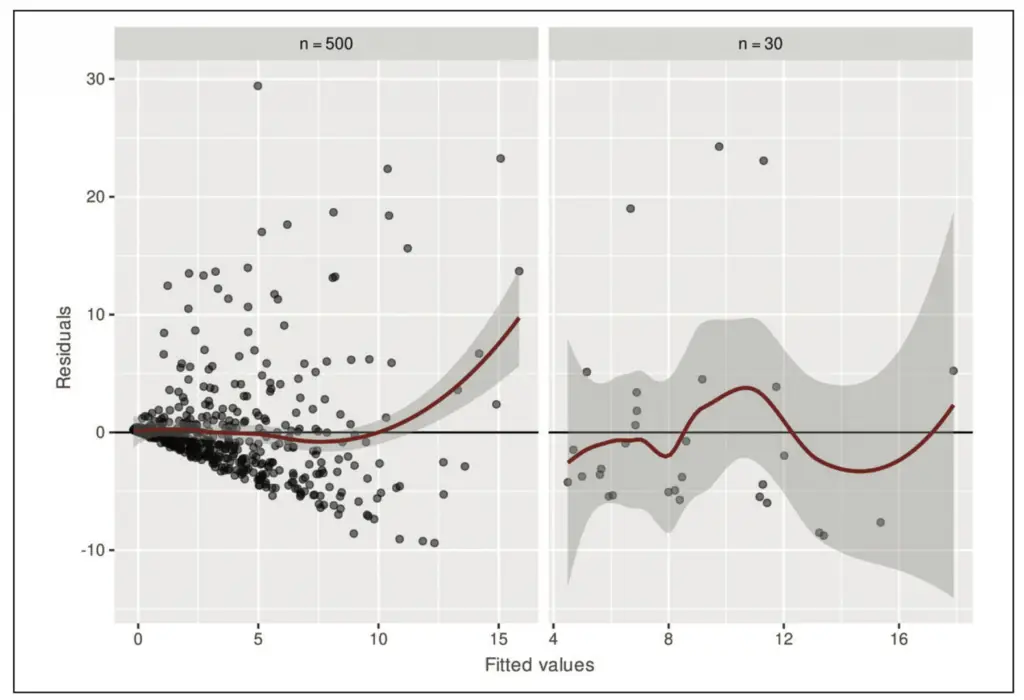
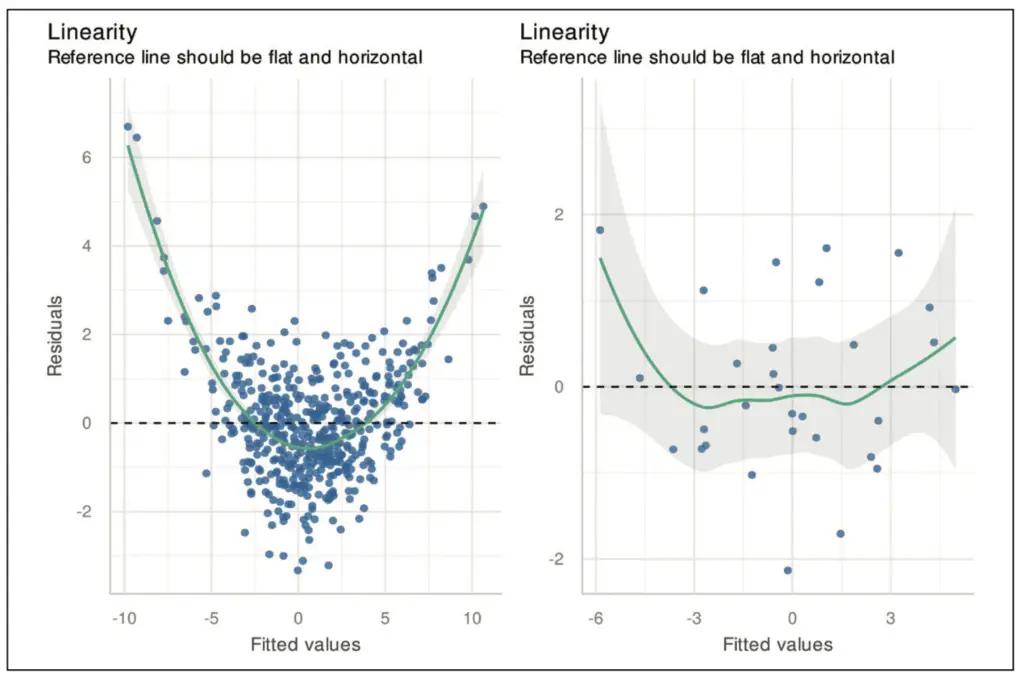
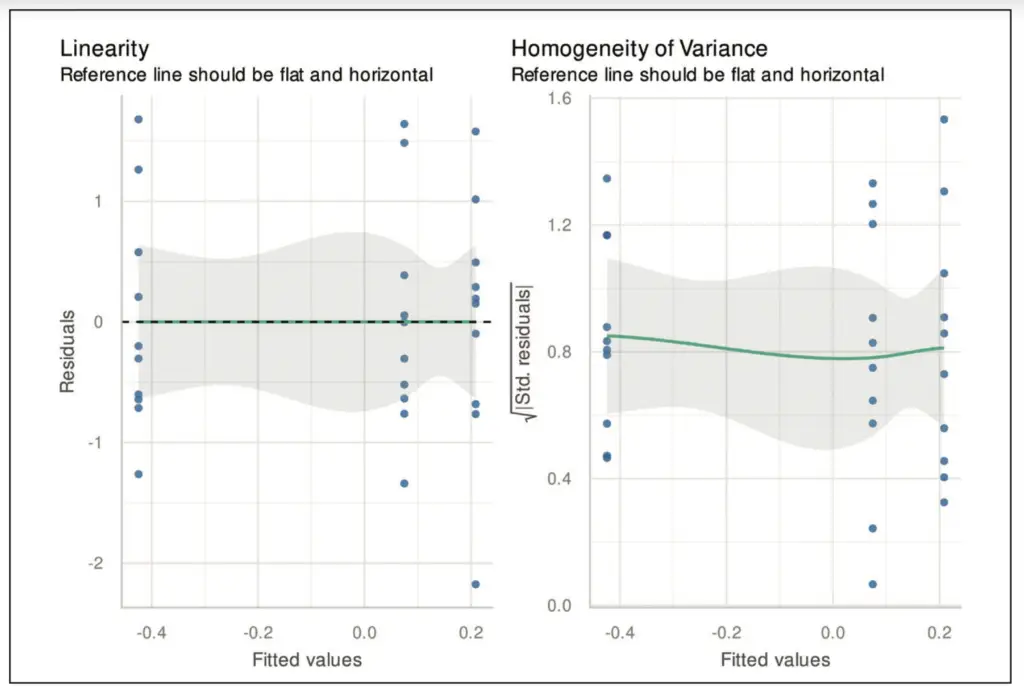
In Abbildung 2 ist eine Situation dargestellt, in der die Varianz der Residuen von der Größe der Beobachtungen abhängt. Während im linken Plot eine Kegelform der Punktewolke deutlich erkennbar ist, wirkt der rechte Plot in dieser Hinsicht unauffällig. Eine kegelförmige Struktur deutet häufig auf einen multiplikativen Fehler hin, d. h. y = x*ε. In diesen Fällen kann daher oft der Logarithmus als varianzstabilisierende Transformation helfen. Wir erhalten
y = log(x*ε) = log(x) + log(ε)
und damit einen additiven Fehler mit einer von x unabhängigen Varianz. Neben einer Variablentransformation kann bei Vorliegen einer Heteroskedastizität auch der Übergang zu einer gewichteten linearen Regressionsanalyse oder einem verallgemeinerten linearen Modell, welches eine allgemeine Fehlerkovarianz erlaubt, helfen (vgl. Abschnitt 8.2.5 in [4]). In der Regel wird diesem Residuenplot zusätzlich eine nichtparametrische Kurvenanpassung hinzugefügt, um mögliche Strukturen leichter erkennen zu können. Im vorliegenden Fall wurde hierfür eine lokal polynomiale Regression (kurz: loess) verwendet [5].
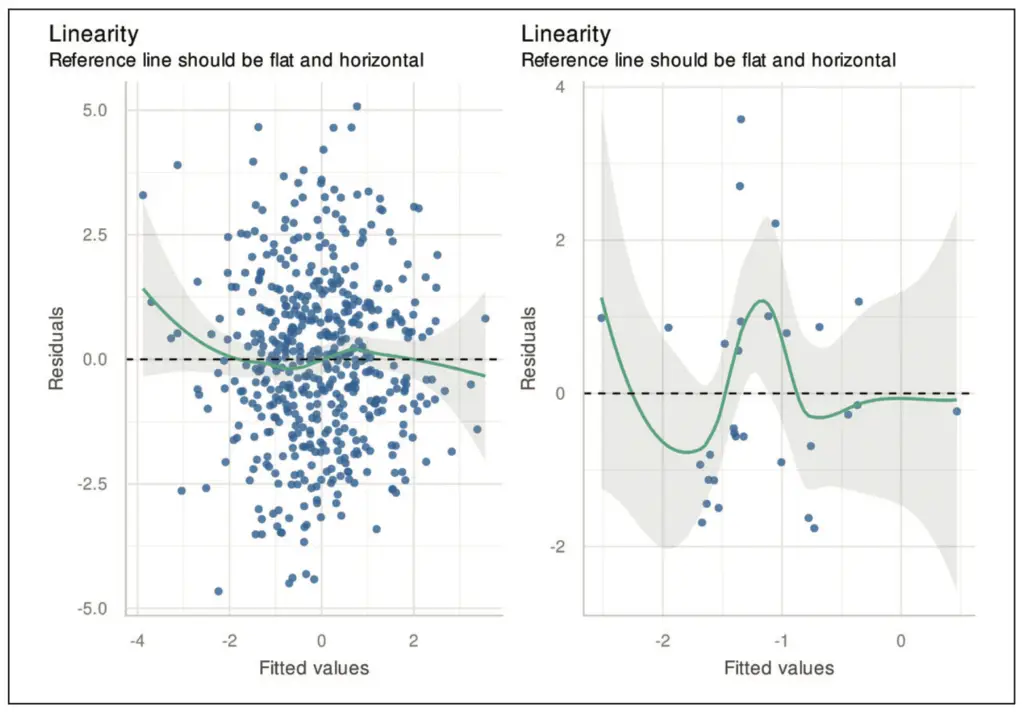
In Abbildung 3 sehen wir den Fall, dass das Modell unvollständig ist. Es fehlt ein quadratischer Anteil. Im besten Fall kann man aus der Struktur der Residuen recht gut schließen, welche Form die noch nicht durch das Modell abgedeckte Information besitzt (vgl. linker Plot). Im rechten Plot würde man nicht von einer signifikanten Abweichung von der Null-Linie ausgehen, was anhand des eingezeichneten Konfidenzbandes zu sehen ist. Zeigt sich eine Struktur in den Residuen, kann diese oft durch die Aufnahme weiterer Regressoren bzw. zusätzlicher Terme der bereits enthaltenen Regressoren (z. B. nicht nur lineare, sondern auch quadratische Terme) beseitigt werden.
Die Abbildung 4 zeigt den Fall, dass keine unabhängigen Beobachtungen, sondern eine Zeitreihe vorliegt. In beiden Fällen ist trotzdem kein starker Trend erkennbar. In der Praxis kann dieser Fall aber meist durch fachliche Überlegungen ausgeschlossen werden.
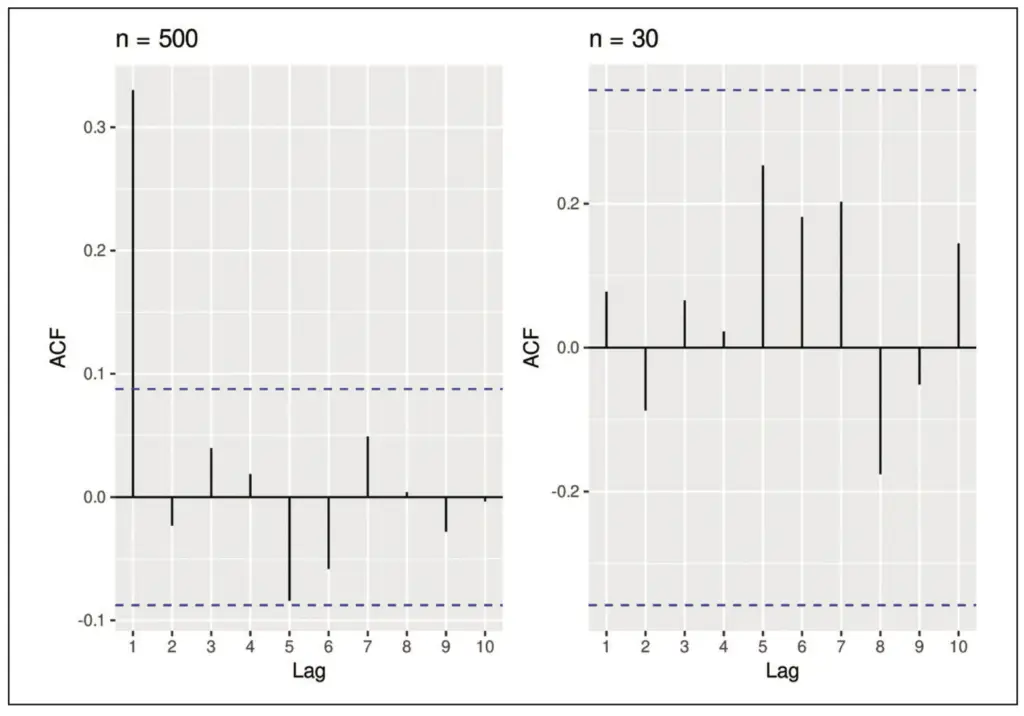
Sollte dies nicht möglich sein, empfiehlt sich zusätzlich ein Plot der Autokorrelationsfunktion (ACF). Diese Funktion erhält man, indem man die Residuen als Zeitreihe auffasst und die Korrelationen zwischen dieser Zeitreihe und den um einen oder mehrere Zeitpunkte (lags) nach rechts verschobenen Zeitreihen berechnet. In Abbildung 5 sind die Ergebnisse für die Residuen aus Abbildung 4 zu sehen. Im linken Plot ist eine signifikante Korrelation zwischen den Residuen und den um einen Zeitpunkt (lag) verschobenen Residuen zu erkennen (die Linie zum lag 1 reicht bis über die blau gestrichelte Grenze hinaus). Im rechten Plot werden hingegen keine signifikanten Korrelationen angezeigt. Liegt tatsächlich eine Zeitreihe vor, sollte statt des linearen Modells ein Zeitreihenmodell verwendet werden.
Skala-Lokation-Plot
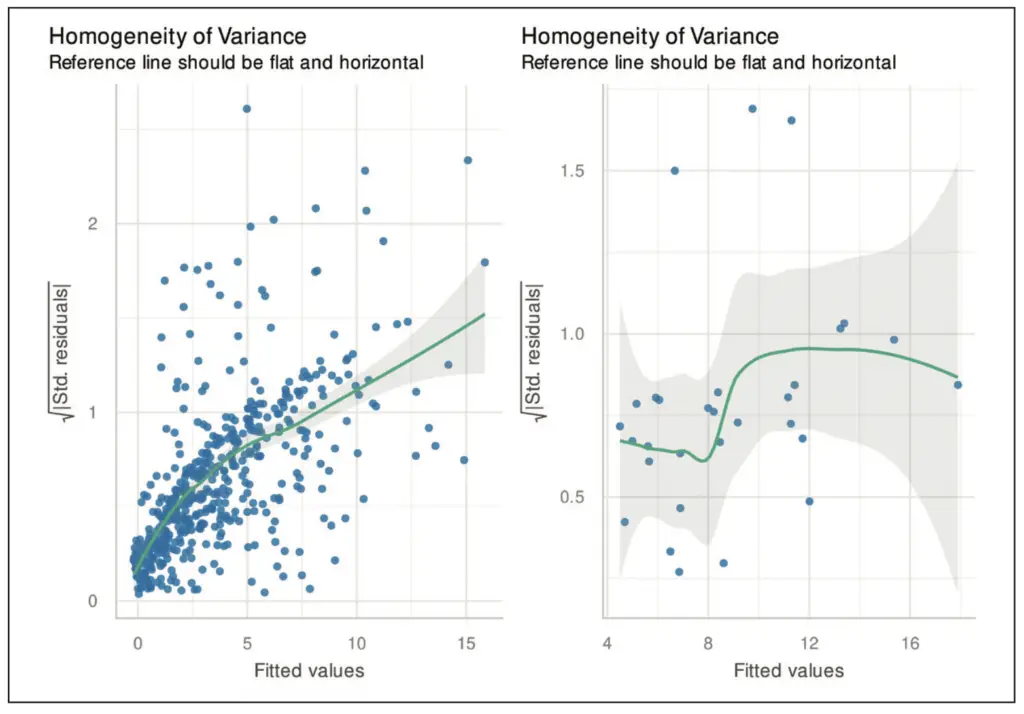
Beim Skala-Lokation-Plot werden die Quadratwurzeln der standardisierten Residuen gegen die gefitteten Werte aufgetragen. Dieser Plot eignet sich besser als der Tukey-Anscombe-Plot, um Abweichungen von der Homoskedastizität zu erkennen. In Abbildung 6 sehen wir das Ergebnis für die in Abbildung 2 dargestellten Residuen. Im linken Plot erkennen wir eine deutlich ansteigende Linie, die ein klares Zeichen für das Vorliegen von Heteroskedastizität ist. Im rechten Plot fällt die Entscheidung schwer und es könnte durchaus eine homoskedastische Situation vorliegen. Wie bereits beim Tukey-Anscombe-Plot erläutert, können eine Variablentransformation oder die Verwendung einer gewichteten oder verallgemeinerten linearen Regression dabei helfen, die Heteroskedastizität zu verringern bzw. zu entfernen (vgl. Abschnitt 8.2.5 in [4]).
qq-Plot
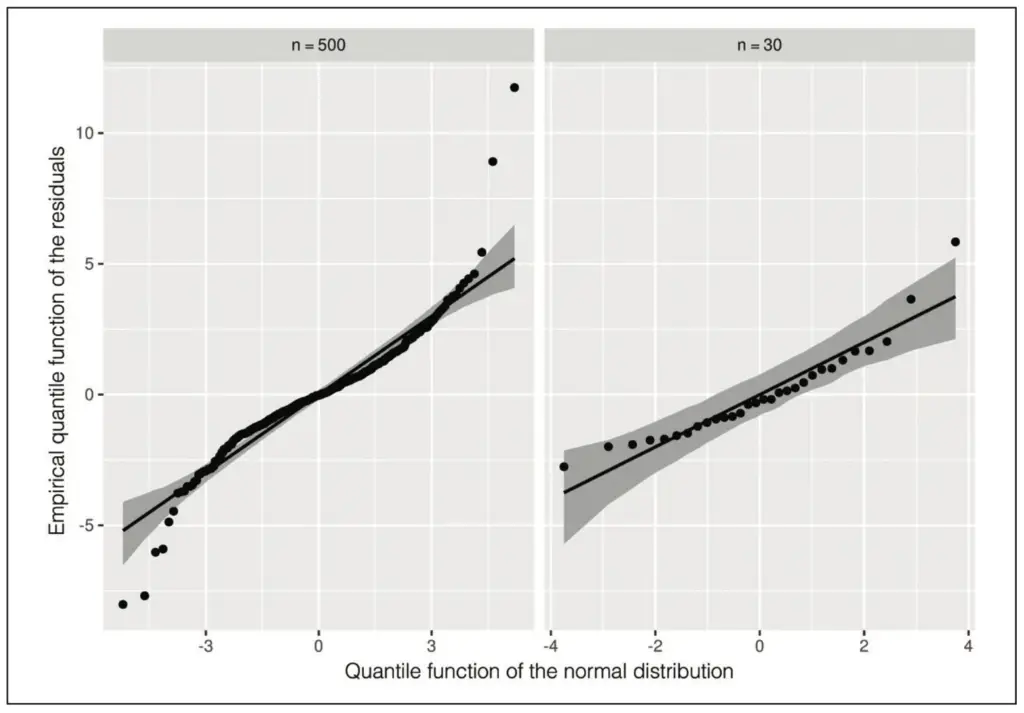
Der qq-Plot wird verwendet, um die Normalverteilung der Residuen zu untersuchen [8]. In Abbildung 7 sind qq-Plots für eine Situation dargestellt, in der die Fehlerverteilung breiter als eine Normalverteilung ist (vgl. auch Abb. 3 in [8]). Während im linken Plot eine klare Struktur erkennbar ist, könnte man im rechten Bild durchaus von einer Normalverteilung der Residuen ausgehen. Liegt eine Abweichung von der Normalverteilung vor, kann versucht werden, durch eine Variablentransformation eine Normalisierung zu erreichen. Alternativ kann auch der Übergang zu einem generalisiert linearen Modell in Erwägung gezogen werden.
Residuen versus Hebelwerte
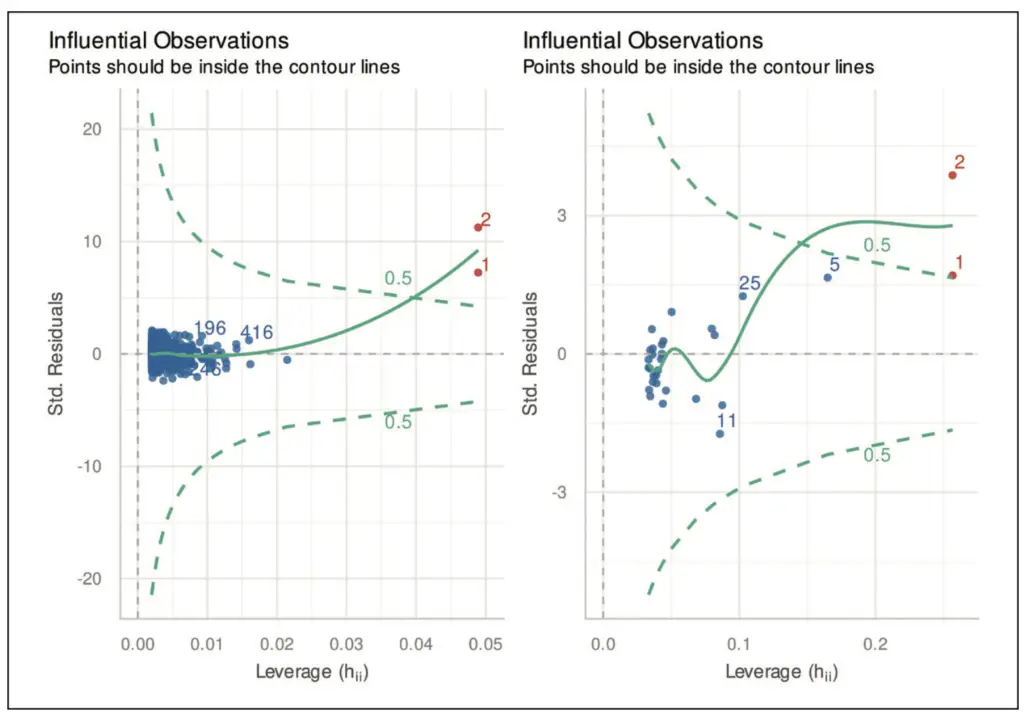
In diesem Plot werden die standardisierten Residuen gegen die Hebelwerte aufgetragen. Der Hebelwert einer Beobachtung beschreibt da-bei deren Einfluss auf das gefittete Modell. Man spricht in diesem Zusammenhang auch von der Hebelwirkung der Beobachtung (vgl. Abschnitt 8.2.4 in [9]). Generell sind beim Vorliegen von n Beobachtungen Werte zwischen 1/n und 1 möglich. Der Mittelwert der Hebelwerte ist (k+1)/n, wobei k die Anzahl der im Modell enthaltenen Variablen ist. Werte größer als 3(k+1)/n werden bei kleinen Fallzahlen und Werte größer als 2(k+1)/n bei großen Fallzahlen als auffällig angesehen. Zusätzlich zum Hebelwert wird oft auch der Cook-Abstand D eingezeichnet (vgl. Ab-schnitt 8.2.4 in [9]). Als Faustformeln für auffällige Werte bezüglich des Cook-Abstands werden häufig D > 1 oder D > 4/n verwendet. In Abbildung 8 sind zwei einflussreiche Hebelpunkte zu sehen, wobei hier eine Grenze von D = 0,5 angenommen wird.
Tritt eine solche auffällige Beobachtung auf, sollte man sorgfältig prüfen, ob die Werte dieser Beobachtung korrekt sind bzw. sein können, oder ob es sich wahrscheinlich um einen Ausreißer handelt. Handelt es sich um korrekte Werte, sind diese sogar hilfreich und können die Genauigkeit des Modells erhöhen. Handelt es sich hin-gegen um potenzielle Ausreißer, sollte man im Rahmen einer Sensitivitätsanalyse das Modell auch ohne diese auffälligen Werte berechnen und beide Modelle miteinander vergleichen.
Multikollinearität
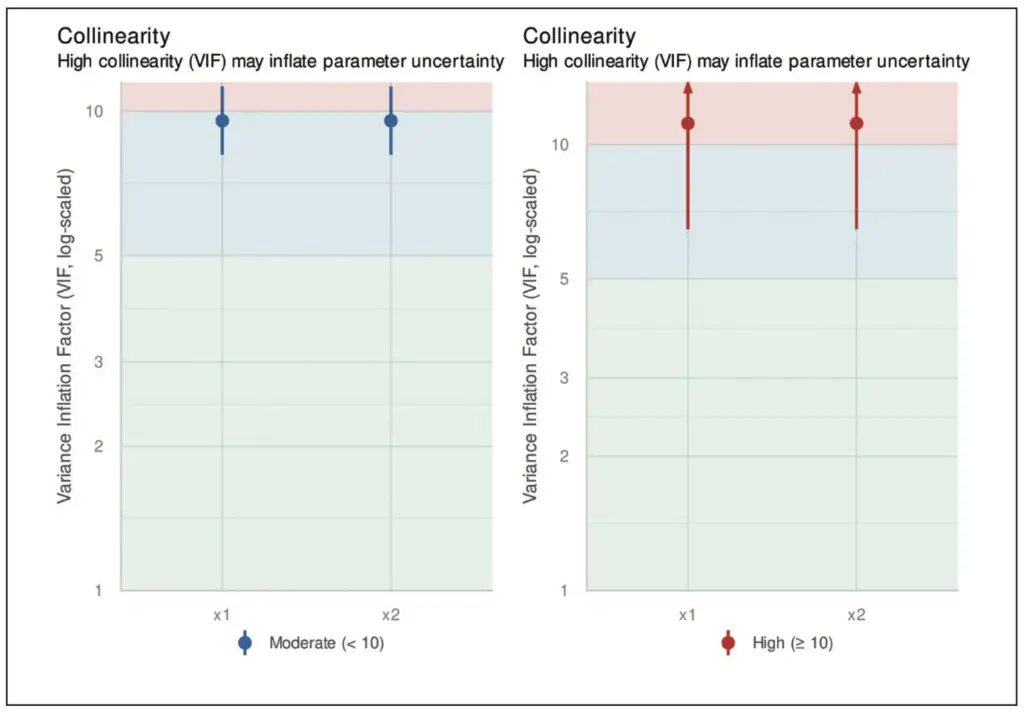
Eine Situation, die bei einer multiplen Regressionsanalyse auftreten kann, ist die sogenannte Multikollinearität. Sie führt zu einer Instabilität des Modells, sodass kleine Veränderungen der Daten zu großen Veränderungen der geschätzten Koeffizienten führen können. Auf die vorhergesagten Werte hat eine Multikollinearität aber oft nur einen geringen Einfluss [1]. In Abbildung 9 ist der Varianzinflationsfaktor (VIF) [1] für eine Situation dargestellt, in der ein Modell die beiden Variablen x1 und x2 enthält, welche eine Korrelation von 0,95 zueinander besitzen. Die Multikollinearität lässt sich beheben, indem einer der hochkorrelierten Regressoren aus dem Modell entfernt wird.
Posterior Vorhersage
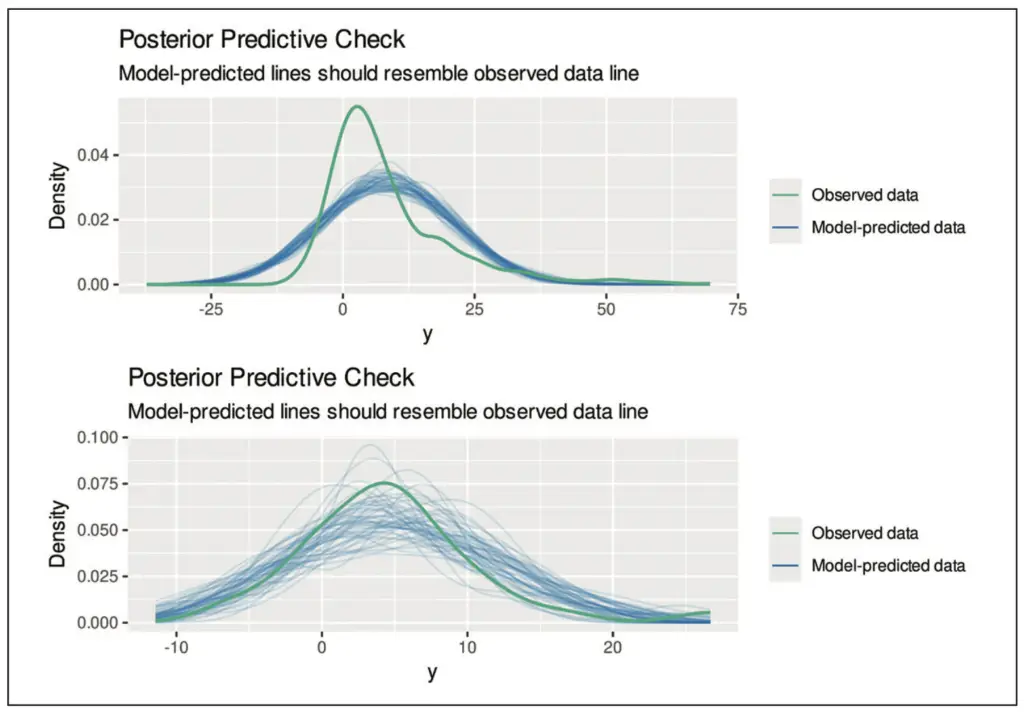
Auf Basis des berechneten Modells simulieren wir wiederholt Daten und vergleichen anschließend deren Verteilung mit der Verteilung der tatsächlich beobachteten Daten. So können systematische Unterschiede zwischen dem Modell und den beobachteten Daten ermittelt werden [10]. In Abbildung 10 sehen wir ein Beispiel, in dem das Modell nicht zu den Daten passt. In diesem Fall wurde eine wichtige Variable im Modell nicht berücksichtigt. Derartige Abweichungen sind dann üblicherweise auch in einem oder mehreren der anderen diagnostischen Plots zu sehen und erfordern eine genauere Analyse. Je nach vermuteter Situation kann eine der im Rahmen der anderen diagnostischen Plots beschriebenen Lösungsmöglichkeiten dabei helfen, das Problem zu beheben.
In den bisherigen Szenarien waren nur quantitative unabhängige Variablen beteiligt. Bei einer ANOVA bzw. ausschließlich diskreten Regressoren zeigt sich ein etwas anderes Bild. In Abbildung 11 sind zwei der zuvor vorgestellten Residuenplots für eine 1-Weg-ANOVA mit drei Gruppen zu sehen. In diesem Fall liegen keine Abweichungen von den Modellannahmen vor.
Beispiel
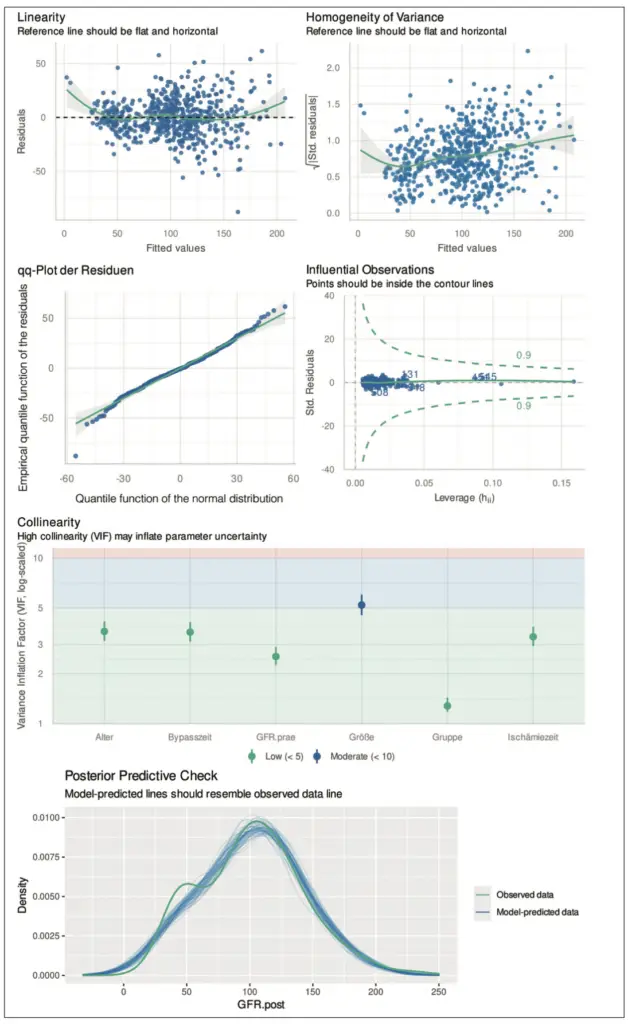
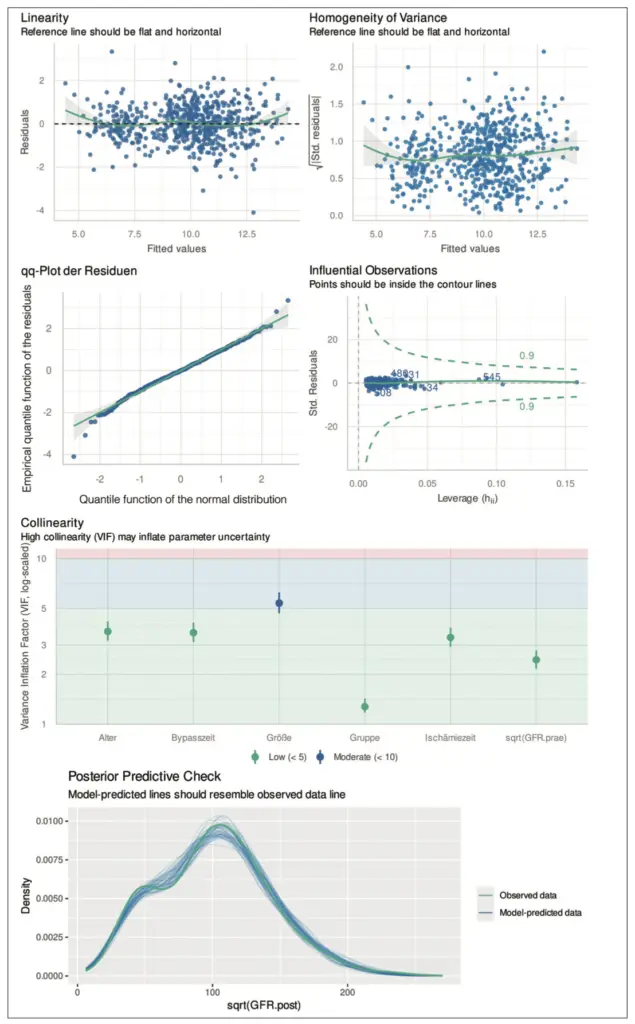
Wir erweitern das Beispiel aus dem Tutorium [1] zur glomerulären Filtrationsrate (GFR) nach einer Herzoperation mit extrakorporaler Zirkulation (EKZ). Dazu berücksichtigen wir neben den GFR-Werten vor der OP auch das Alter und die Körpergröße der Kinder sowie die Dauer des Bypasses und der Ischämie. Da es sich um voneinander (stochastisch) unabhängige Patient:innen handelt, schließen wir das Vorliegen einer (stochastischen) Abhängigkeit aus. Wir verzichten daher auf den Plot der Autokorrelationsfunktion. In Abbildung 12 sind die verbleibenden, zuvor vorgestellten diagnostischen Plots für das berechnete lineare Modell zu sehen. Auch nach der Hinzunahme weiterer Variablen sehen wir ähnliche Auffälligkeiten, wie in [1] berichtet. Es deutet sich eine leichte Heteroskedastizität sowie eine leichte Abweichung von der Normalverteilung an. Darüber hinaus zeigt die posterior Vorhersage eine Abweichung zwischen dem Modell und den Daten. Für die Körpergröße der Kinder ergibt sich eine moderate Multikollinearität. Dies ist nicht überraschend, da die Kinder sehr jung sind (max. 5 Jahre) und somit eine hohe Korrelation zum Alter zu erwarten ist. Tatsächlich liegt die Spearman-Korrelation zwischen Alter und Größe bei 0,892. Da die Multikollinearität jedoch nur moderat ist, stellt dies kein großes Problem dar. Wir belassen daher beide Variablen im Modell. Wie im Tutorium [1] besprochen, führt die Quadratwurzel zu einer Varianzstabilisierung und Normalisierung. Wir wiederholen daher die Analyse und verwenden dabei die Quadratwurzel der GFR-Werte. Die diagnostischen Plots in Abbildung 13 zeigen eine Abnahme der Heteroskedastizität und der Abweichung von der Normalverteilung sowie eine gute Übereinstimmung zwischen Daten und Modell. Die Adjustierung auf weitere Variablen beeinflusst auch die Unterschiede zwischen den drei betrachteten Gruppen (Gruppe 1: „venöses Pooling“ mit Nitroprussid, Gruppe 2: „venöses Pooling“ mit Nitroglycerin, Gruppe 3: ohne Intervention). Im Unterschied zur Analyse in Tutorium [1], ist der Unterschied zwischen Gruppe 1 und Gruppe 2 nicht (mehr) signifikant (p = 0,066), während die Unterschiede zwischen Gruppe 1 und Gruppe 3 (p < 0,001) sowie zwischen Gruppe 2 und Gruppe 3 (p = 0,003) weiterhin signifikant sind. Die Adjustierung auf weitere Variablen hat demnach dazu geführt, dass die Gruppen 1 und 2 näher zueinander gerückt sind.
Zusammenfassung
Diagnostische Plots sind wichtige grafische Hilfsmittel, um die Voraussetzungen der verwendeten Modelle zu überprüfen. Im Fall der linearen Regression gibt es eine ganze Reihe von Plots, die zur Diagnostik herangezogen werden können und sollten. Die meisten dieser Plots basieren auf den Residuen des berechneten linearen Modells, weshalb auch von Residuendiagnostik gesprochen wird. Die Plots eignen sich sehr gut, um zu prüfen, ob die notwendigen Voraussetzungen für das vorliegende lineare Modell erfüllt sind. Generell ist jedoch eine gewisse Erfahrung erforderlich, um diese Plots sicher interpretieren zu können. Gerade bei kleinen bis moderaten Stichprobengrößen ist es schwierig, Abweichungen zu erkennen und eine zuverlässige Aussage über das Vorliegen der entsprechenden Voraussetzungen zu treffen. Bei Unklarheiten empfiehlt es sich, einen Statistiker zu Rate zu ziehen.
Literatur
- Kohl M, Münch F. Statistik Teil 13: Lineare Regression. Die Perfusiologie 2025 (1): 26-31.
- Wickham H. ggplot2: Elegant graphics for data analysis, 2016. Springer-Verlag New York.
- R Core Team. R: a language and environment for statistical computing. R Foundation for Statistical Computing, 2025. Vienna, Austria. URL https://www.R-project.org/.
- Hedderich J, Sachs L. Angewandte Statistik. Methodensammlung mit R, 2020. 17. Auflage, Springer-Verlag.
- Cleveland WS, Grosse E, Shyu WM. Local regression models. Chapter 8 of Statistical Models in S, eds J.M. Chambers and T.J. Hastie, Wadsworth & Brooks/Cole, 2018.
- Lüdecke D, Ben-Shachar MS, Patil I, Waggoner P, Makowski D. Performance: an R package for assessment, comparison and testing of statistical models. Journal of Open Source Software 2021, 6(60), 3139.
- Hyndman RJ, Khandakar Y. Automatic time series forecasting: the forecast package for R. Journal of Statistical Software 2008, 27(3): 1-22.
- Kohl M, Münch F. Statistik Teil 16: pp- und qq-Plot. Die Perfusiologie 2025 (4): 174-179.
- Almeida A, Loy A, Hofmann H. ggplot2 compatible quantile-quantile plots in R. The R Journal 2018, 10(2): 248-261.
- Gelman A, Hill J. Data analysis using regression and multilevel/hierarchical models, 2007. Cambridge, New York: Cambridge University Press.