Einführung
Die lineare Regression ist eines der am häufigsten angewendeten Verfahren in der Statistik. Es wird dabei untersucht, wie gut sich eine abhängige Variable (Response, Zielvariable) durch eine Linearkombination von unabhängigen Variablen (Regressoren, erklärende Variablen) beschreiben lässt. Der t-Test [1], die 1-Weg ANOVA [2] oder auch generell die Varianz- und Kovarianzanalyse (ANOVA und ANCOVA) sind Spezialfälle des linearen Modells. Wir werden in diesem Tutorial kurz das multiple lineare Modell mit den typischen Modellannahmen vorstellen. Unser Augenmerk liegt jedoch nicht auf der Theorie der linearen Modelle, hierzu gibt es eine ganze Reihe von Büchern, sondern darauf, welche speziellen Phänomene im Zusammenhang mit der linearen Regression auftreten können und was man bei der Anwendung von linearen Modellen in der Praxis beachten sollte.
Einfache lineare Regression
Zur Einführung beginnen wir mit der sogenannten einfachen linearen Regression, um einige grundlegende Begriffe und Konzepte einzuführen (vgl. Abschnitt 8.2.1 in [3]). In diesem Fall soll die abhängige Variable y (Skalar) durch eine einzige unabhängige Variable x (Skalar) erklärt werden. Das Modell lautet
y = β0+ β1x + ϵ,
wobei es sich bei ϵ um eine stochastische Fehlervariable handelt, die zufällige Schwankungen in der abhängigen Variable y erzeugt, die nicht durch den Regressor x erklärt werden können. Es geht demnach darum, eine Gerade mit Achsenabschnitt β0 und Steigung β1 zu schätzen. Man nennt β0 und β1 auch die Koeffizienten oder Parameter des Modells. Im Fall, dass es keine erklärenden Variablen gibt, reduziert sich dies auf das so genannte Lokationsmodell, welches im Regressionskontext auch Nullmodell (enthält 0 Regressoren) genannt wird.
y = β0 + ϵ
Für die Bestimmung der Koeffizienten wird üblicherweise die Methode der kleinsten Quadrate verwendet. Dies führt auf die geschätzten (gefitteten) Werte für die Koeffizienten, die üblicherweise mit einem „Hut“ versehen werden, also β0^ und β1^. Entsprechend erhalten wir die geschätzten (gefitteten) Werte für y^ als
y^ = β0^ + β1^ x.
Dies sind folglich die Werte, die durch die gefittete Gerade für die abhängige Variable y vorhergesagt werden. Die Differenz yi – yi^ (i = 1, …, n) zwischen einem beobachteten Wert yi und dem vorhergesagten Wert yi^ nennt man Residuum. Hieraus wird die Summe der Residuenquadrate RSS (residual sum of squares) berechnet
RSS = ![]() (yi – yi^ )2.
(yi – yi^ )2.
Die RSS für das Modell vergleicht man mit der RSS des Nullmodels, welche man auch als TSS (total sum of squares) bezeichnet. Um festzustellen, ob x einen zusätzlichen Erklärungswert liefert, betrachtet man das Verhältnis von RSS zu TSS, wobei aus diesem Verhältnis das Bestimmtheitsmaß R2 abgeleitet wird als
![]()
Es ergibt sich hierfür immer eine Zahl im Bereich von 0 bis 1. Man erhält R2 = 1, falls alle Beobachtungen yi exakt auf der gefitteten Geraden liegen und R2 = 0, falls x keinen Erklärungswert besitzt. Allgemeiner ausgedrückt, entspricht das R2 gerade dem Anteil der Variabilität in den Daten, der durch das Modell erklärt wird. Im Fall der einfachen linearen Regression, entspricht das R2 auch gerade dem Quadrat der Pearson-Korrelation [4]. Es ist zu beachten, dass das R2 generell leicht zu manipulieren ist. Zum Beispiel lässt sich das R2 alleine dadurch erhöhen, indem man weitere Regressoren ins Modell aufnimmt. Wir werden im nächsten Abschnitt daher auch noch weitere Möglichkeiten einführen, mit denen man die Güte eines Modells beurteilen kann.
Multiple lineare Regression
Wir betrachten die Situation, dass mehrere erklärende Variablen x1, x2, …, xp vorliegen. Das multiple lineare Modell besitzt dann die folgende Form (vgl. Abschnitt 8.2.2 in [3]):
y = β0 + β1 x1 + β2 x2 … + βp xp + ϵ.
Die abhängige Variable y lässt sich demnach als eine Linearkombination der unabhängigen Variablen x1, x2, …, xp ausdrücken. Aus dieser Tatsache ergibt sich auch der Name lineares Modell. Alle Variablen sind hier skalar. Kategoriale unabhängige Variablen werden in so genannte Dummy-Variablen (0 bis 1 Variablen) umgewandelt (vgl. Abschnitt 8.2.8 in [3]). So werden aus einer kategorialen Variablen mit k Kategorien dann k Dummy-Variablen, wobei nur k–1 dieser Variablen ins Modell aufgenommen werden, da sich eine der Variablen unmittelbar aus den anderen k–1 Variablen ergibt. Sind alle p-unabhängigen Variablen kategorial, bezeichnen wir dies als p-Weg ANOVA (ANalysis Of VAriance). Werden im Fall der ANOVA zur Adjustierung zusätzliche metrische Variablen (Kovariablen) ins Modell aufgenommen, so spricht man auch von ANCOVA (ANalysis of COVAriance). Das Augenmerk liegt im Fall der ANCOVA wie im Fall der ANOVA auf den kategorialen Variablen.
Die üblichen Voraussetzungen für das multiple lineare Modell sind:
- Es gibt einen inhaltlich begründeten Zusammenhang zwischen x1, x2, …, xp und y; d. h., y ist eine Funktion von x1, x2, …, xp.
- Die Varianz der y-Werte ist unabhängig von den Regressoren x1, x2, …, xp und konstant; d. h.
Var(y | x1, x2, …, xp ) = σ2.
- Die Beobachtungen sind voneinander (stochastisch) unabhängig; d. h., es liegt keine Zeitreihe vor.
- Für die Berechnung des Schätzers wird zusätzlich benötigt, dass der Erwartungswert des Zufallsfehlers ϵ gleich 0 ist (E(ϵ) = 0) und die Varianz gleich σ2 ist (Var(ϵ) = σ2).
- Für die Berechnung von Konfidenzintervallen und statistischen Tests wird zusätzlich vorausgesetzt, dass der Zufallsfehler normalverteilt ist.
Falls Abweichungen von den Voraussetzungen (0) bis (4) vorliegen, so kann man versuchen, diese Abweichungen durch Transformationen der Variablenauszugleichen. Für die Transformation der Variablen kommt im Prinzip jede beliebige Funktion in Frage. Eine ganze Reihe von möglichen Transformationen sind etwa im Paket BestNormalize [5] für die Statistiksoftware R [6] enthalten.
Man spricht von einem multivariaten linearen Modell, wenn man es nicht mit skalaren, sondern mit vektorwertigen Variablen zu tun hat. Man nennt dies auch allgemeines lineares Modell. Dieses Modell muss man unterscheiden von einem generalisiert linearen Modell, bei dem die sogenannte Linkfunktion den linearen Zusammenhang zwischen der abhängigen Variablen y und den unabhängigen Variablen x1, x2, …, xp herstellt. Diese beiden Modelle werden wir hier jedoch nicht genauer betrachten und verweisen stattdessen auf eine Vielzahl von Lehrbüchern, die es dazu gibt [7,8,9].
Wie bereits erwähnt, lässt sich das Bestimmtheitsmaß R2 zum Beispiel durch die Aufnahme weiterer Variablen erhöhen. Aus diesem Grund sollte man beim Vergleich von zwei Modellen, die unterschiedlich viele Variablen beinhalten, nicht das R2 heranziehen. Besser geeignet ist das folgende adjustierte R2 [10]:
![]()
Die Anzahl der Variablen p sowie die Stichprobengröße n werden hier zusätzlich berücksichtigt. Sollten zwei Modelle das gleiche R2 aufweisen, aber unterschiedlich viele Variablen beinhalten, so hat das Modell mit der geringeren Anzahl von Variablen das höhere R adj 2. Weitere Kriterien, die zum Vergleich von Modellen herangezogen werden können, sind die Mallows’ Cp Statistik [11]
![]()
wobei σ^ 2 die Varianz der Residuen ist. Unter der Annahme (4) ist die Mallows’ Cp Statistik äquivalent zum Akaike Informationskriterium (AIC) [12], welches definiert ist als
AIC = – 2log(L) + 2p,
wobei L für das Maximum der Likelihood Funktion steht. Ein weiteres häufig verwendetes Kriterium ist das Bayessche Informationskriterium (BIC) [13]
![]()
bei dem der Faktor 2 in der Mallows’ Cp Statistik durch log(n) ersetzt ist. Da log(n) > 2 für n > 7, werden Modelle mit mehr Variablen vom BIC-Kriterium stärker „bestraft“ als von der Cp Statistik. Bei allen drei Statistiken ist das Modell mit den kleineren Werten besser.
Phänomene im Zusammenhang mit der linearen Regression
Im Zusammenhang mit Regressionsanalysen zeigen sich verschiedene Phänomene, deren Ursache und Bedeutung man sich bewusst sein sollte.
Ein erstes Phänomen, welches man beobachten kann, ist die sogenannte Regression zur Mitte (regression towards the mean/mediocrity), dessen Entdeckung man meist Francis Galton (1822–1911) zuschreibt [14]. Er beobachtete, dass kleine Väter relativ gesehen größere Söhne haben und umgekehrt, dass große Väter relativ gesehen kleinere Söhne haben. Das Phänomen tritt immer dann auf, wenn wir Messungen haben, die eine gewisse zufällige Variabilität aufweisen. Führt man eine Messung durch und erhält ein Ergebnis, welches weit vom (unbekannten) Mittel entfernt liegt, dann ist es wahrscheinlich, dass man in einer Wiederholungsmessung ein Ergebnis bekommt, welches näher beim (unbekannten) Mittel liegt. Dieser Effekt lässt sich in vielen Studien beobachten, in denen Patient:innen aufgrund sehr hoher oder sehr niedriger Ausgangswerte in die Studie eingeschlossen wurden. Ähnliches gilt auch für kleine Studien, in denen große Effekte gefunden wurden. Werden diese Studien mit größeren Fallzahlen wiederholt, so ergeben sich oft deutlich kleinere Effekte [15]. Die Regression zum Mittel ist ein rein statistischer Effekt ohne kausale Ursache. Man sollte demnach auch nicht nach einer Ursache suchen.
Ein zweites Phänomen ist das sogenannte Simpson Paradoxon. Es wurde von Simpson (1951) [16] im Zusammenhang mit Kontingenztafeln [17] beschrieben, kann jedoch auch im Rahmen von Regressionsanalysen und jeglichen Analysen mit multiplen Variablen auftreten. Wird eine wichtige Variable, wie etwa relevante Untergruppen, nicht berücksichtigt, kann dies zu völlig falschen Ergebnissen führen. In komplexen Systemen, wie wir diese in der Biologie und Medizin betrachten, ist es schwierig alle Variablen zu messen, geschweige denn überhaupt zu kennen. Damit kann man in solchen Situationen dieses Paradoxon nie ganz ausschließen. Entsprechend sollte man daher die Ergebnisse immer vorsichtig interpretieren.
Ein drittes Phänomen, welches im Zusammenhang mit der linearen Regression möglich ist, ist die sogenannte Multikollinearität (vgl. Abschnitt 8.2.3 in [3]). Diese tritt dann auf, wenn es eine hohe (multiple) Korrelation zwischen den unabhängigen Variablen gibt. Dieses Phänomen kann man nahezu immer in mehr oder weniger starker Form beobachten, da eine gewisse Korrelation zwischen den unabhängigen Variablen typisch ist, da diese Variablen oft ähnliche Informationen über die abhängige Variable enthalten. Falls eine Multikollinearität vorliegt, können kleine Änderungen in den Daten zu großen Veränderungen bei den geschätzten Koeffizienten führen. Im Gegensatz dazu hat eine Multikollinearität oft nur einen sehr kleinen Effekt auf die vorhergesagten Werte yi^. Das bedeutet, dass auch bei Vorliegen einer Multikollinearität das Modell immer noch brauchbare Vorhersagen liefern kann. Jedoch sollte man bei der Interpretation der geschätzten Koeffizienten und des Modells selbst sehr vorsichtig vorgehen. Liegt eine Multikollinearität vor, so kann man diese auflösen, indem man die Variable, die diese verursacht, aus dem Modell entfernt.
Für das Aufspüren des Verursachers einer Multikollinearität kann man verschiedene Kriterien heranziehen. Man kann paarweise Korrelationen zwischen den unabhängigen Variablen berechnen oder den Varianzinflationsfaktor (VIF) bestimmen. Der VIF ergibt sich, indem man anstelle von y der Reihe nach alle xj (j = 1, 2, …, p) als abhängige Variablen verwendet und die verbleibenden Variablen xi (i ≠ j) als unabhängige Variablen nutzt. Dies führt auf die Bestimmtheitsmaße Rj 2 und wir erhalten
VIF = (1 – Rj 2)-1.
Falls VIF >10, liegt möglicherweise eine Multikollinearität vor. Falls VIF >100, kann man relativ sicher von einer Multikollinearität ausgehen. Eine weitere Möglichkeit besteht darin, die sogenannte Kondition des linearen Modells zu berechnen. Falls diese im Bereich von 10–30 liegt, spricht man von einer moderaten Multikollinearität. Ist diese >100, so liegt eine starke Multikollinearität vor.
Modellwahl
Heute werden in Studien in der Regel eine Vielzahl von Variablen erhoben, weshalb man sich häufig damit beschäftigen muss, welche der Variablen wirklich im Modell berücksichtigt werden sollen. Hierfür sollten in erster Linie fachliche Überlegungen herangezogen werden. Es gibt aber auch verschiedene statistische Lösungen (vgl. Abschnitt 8.2.7 in [3]).
Zum Beispiel kann man folgende Ansätze verwenden:
- Betrachte alle möglichen Teilmodelle und wähle das „beste” (2p – 1 Modelle!).
- Starte mit dem Nullmodell und füge Schritt für Schritt jeweils die „beste” Variable hinzu bis das „optimale” Modell erreicht ist (Vorwärts-Einschluss).
- Starte mit dem Modell mit allen Variablen und entferne Schritt für Schritt jeweils die „schlechteste” Variable bis das „optimale” Modell erreicht ist (Rückwärts-Elimination).
- Kombiniere Vorwärts-Einschluss und Rückwärts-Elimination.
Als Kriterien zur Auswahl des besten Modells können das adjustierte R2, die Mallows’ Cp Statistik, das AIC- oder BIC-Kriterium oder auch statistische Tests herangezogen werden. Wendet man diese Ansätze auf den gesamten vorliegenden Datensatz an, so muss man davon ausgehen, dass die Ergebnisse für das ausgewählte Modell zu optimistisch sind und es auch Variablen enthält, die nur zufällig als wichtig eingestuft wurden und keinen echten Erklärungswert haben. Auch ist es möglich, dass wichtige Variablen ausgeschlossen wurden, da diese zusätzlich zu den bereits im Modell enthaltenen Variablen keinen neuen Erklärungswert liefern. Man spricht in diesem Zusammenhang auch von Wiedereinsetzungsbias (resubstitution bias) und Modellwahlbias (model selection bias), da die Modelle auf Basis derselben Daten bewertet werden, mit denen sie auch berechnet wurden (resubstitution) und aus vielen Modellen ein bestes ausgewählt (model selection) wird [18]. Man kann diese beiden Fehlerquellen kontrollieren, wenn zusätzlich sogenannte Resamplingmethoden wie Bootstrap oder Kreuzvalidierung zum Einsatz kommen. Dies wird auch interne Validierung genannt. Es kann für die Modellbewertung auch ein unabhängiger Datensatz aus einer separaten Studie herangezogen werden. In diesem Fall spricht man von externer Validierung [18].
Eine alternative Herangehensweise stellt die Lasso Regression [19] dar, bei der durch einen zusätzlichen Strafterm bei der Bestimmung des optimalen Modells die Gefahr reduziert wird, dass es zu einer sogenannten Überanpassung (overfitting) kommt und zu den oben genannten Verzerrungen.
Modelldiagnostik
Nachdem das (optimale) Modell bestimmt wurde, sollte man prüfen, ob die Voraussetzungen (0)-(4) für dieses Modell erfüllt sind, bevor man das Modell im Detail interpretiert. Sollten nämlich eine oder mehrere der Voraussetzungen verletzt sein, so kann die Bestimmung der Koeffizienten oder auch die Berechnung von Tests oder Konfidenzintervallen fehlerhaft sein. Für die Überprüfung der Voraussetzungen stehen verschiedene statistische Tests zur Auswahl. Hierbei sollte man jedoch beachten, dass diese Tests meist nur bestimmte und nicht etwa jegliche Art von Abweichungen erkennen. Die Tests besitzen demnach nur eine begrenzte Power zur Aufdeckung von Abweichungen. Daher ist es üblich, die Diagnostik unter Verwendung von graphischen Darstellungen durchzuführen, wobei hierfür in erster Linie die Residuen herangezogen wer- den (vgl. Abschnitt 8.2.4 in [3]). Wir werden hierauf im Rahmen des folgenden Beispiels genauer eingehen.
Beispiel
Für ausführliche Beispiele zum t-Test und zur 1-Weg ANOVA verweisen wir auf unsere Tutorien hierzu [1,2]. Wir erweitern das Beispiel aus [2] zur glomerulären Filtrationsrate (GFR) nach einer Herzoperation mit extrakorporaler Zirkulation (EKZ) zu einer ANCOVA, indem wir zusätzlich auf die GFR-Werte vor der OP adjustieren. Es liegen drei Gruppen vor, wobei eine Gruppe zum „venösen Pooling“ Nitroprussid und eine zweite Gruppe alternativ Nitroglycerin erhielt. Eine Gruppe war ohne Intervention. Die Gruppen bestehen zusammen aus 614 Patient:innen (Nitroprussid: 219, Nitroglycerin: 176, ohne Intervention: 219), wobei durch fehlende Werte nur 592 Patient:innen in die ANCOVA eingehen (Nitroprussid: 214, Nitroglycerin: 167, ohne Intervention: 211). Wir erhalten einen signifikanten Unterschied zwischen den Gruppen (p = 1.2 x 10-12), wobei R2 = 0.785 und R adj2 = 0.784. Jedoch können wir anhand der beiden Darstellungen der Residuen in Abbildung 1 erkennen, dass die Annahme einer konstanten Varianz verletzt ist. Dies sieht man daran, dass die Residuen im linken Plot eine keilförmige Punktwolke bilden (Streuung nimmt von links nach rechts zu) und die Kurve im rechten Plot von links nach rechts deutlich ansteigt. Man spricht in diesem Fall auch von einer Heteroskedastizität der Residuen.
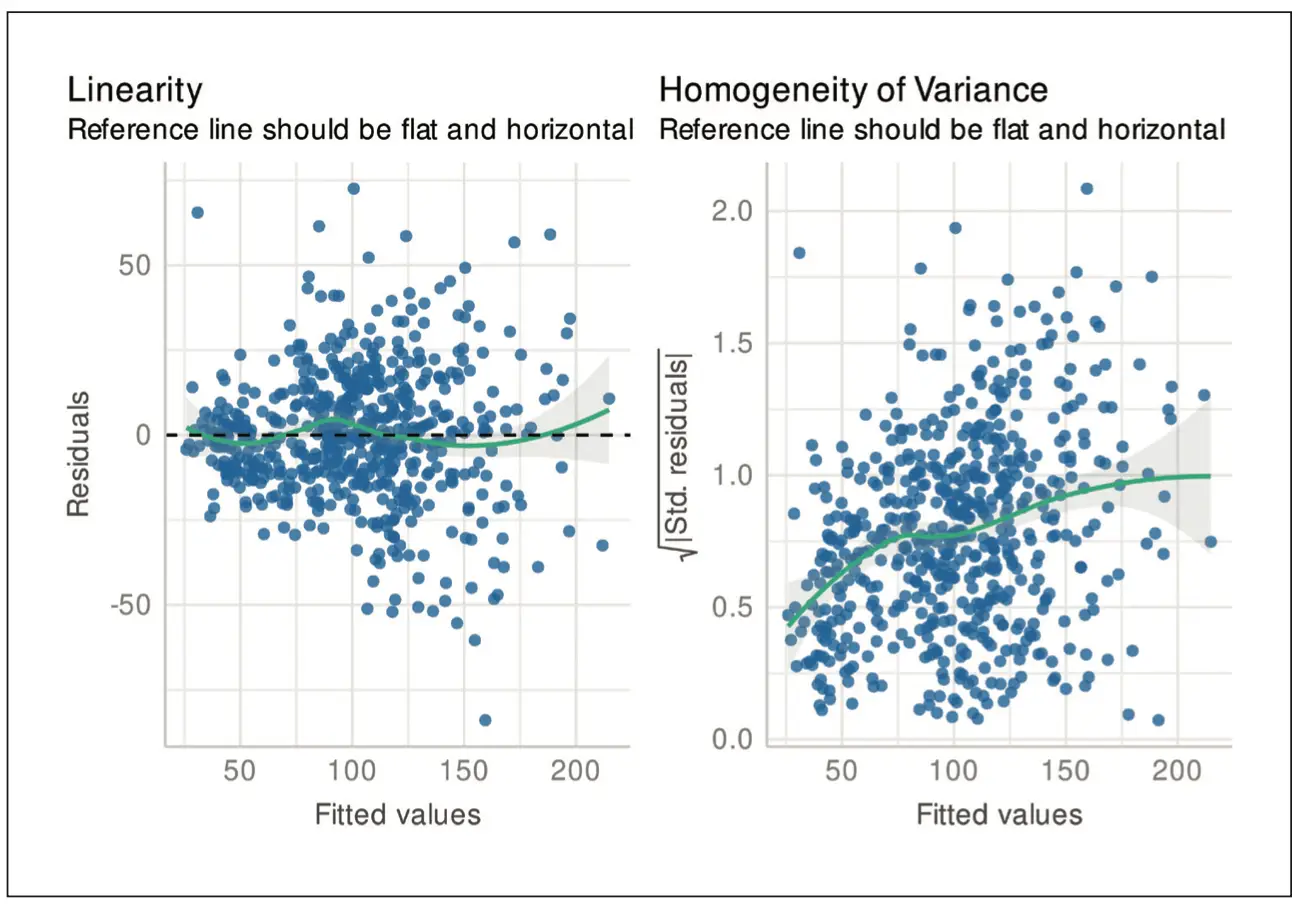
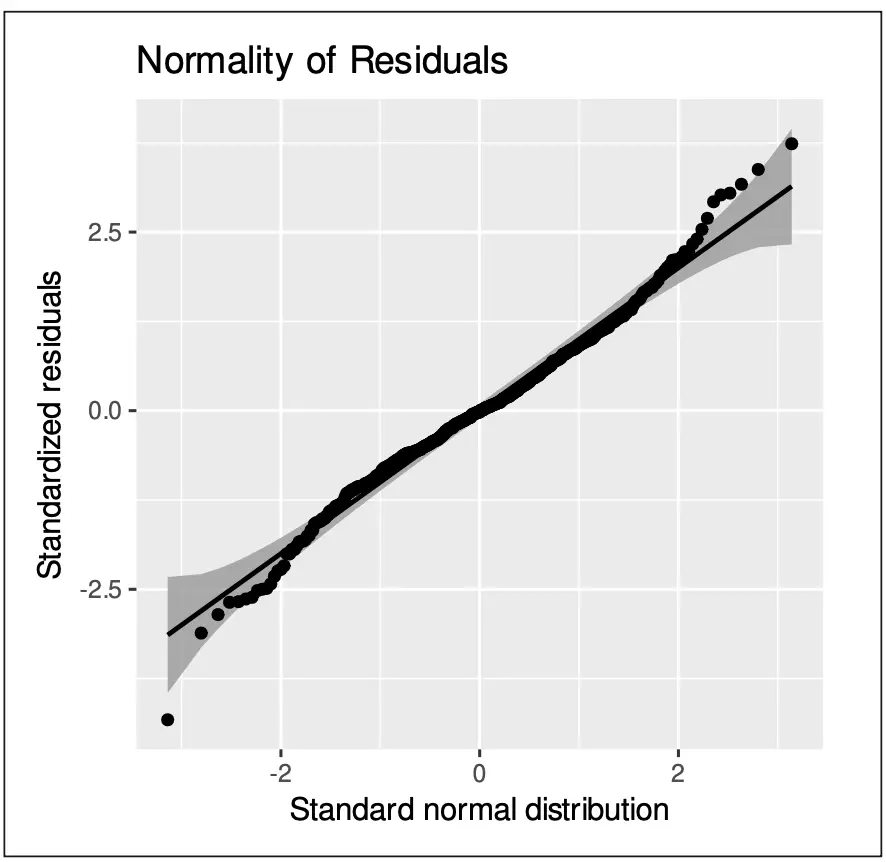
Der qq-Plot in Abbildung 2, in dem die empirischen Quantile der standardisierten Residuen mit den theoretischen Quantilen der Standardnormalverteilung verglichen werden, zeigt außerdem, dass gewisse Abweichungen von der Normalverteilung vorliegen.
Wir sollten daher mit der Interpretation der Ergebnisse vorsichtig sein. Eine Möglichkeit, mit dieser Situation umzugehen, besteht darin, eine geeignete Transformation für die Daten zu finden, welche die Heteroskedastizität und die Abweichungen von der Normalverteilung reduziert oder idealerweise sogar komplett entfernt. Das Paket bestNormalize [6] liefert im vorliegenden Fall die Quadratwurzel als eine mögliche Transformation.
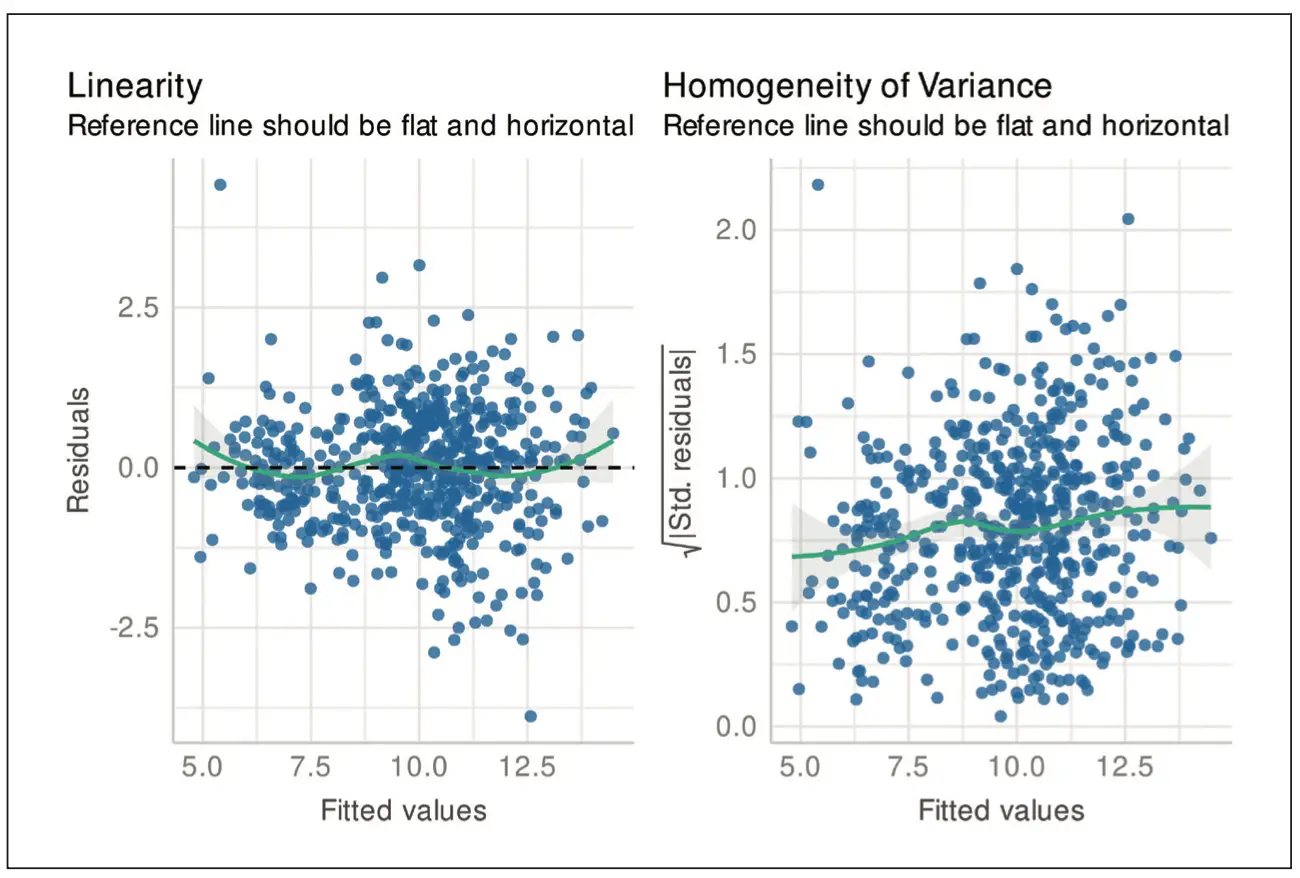
Wir wiederholen die Berechnungen, wobei wir die Quadratwurzel der GFR-Werte (prä- und post-OP) verwenden. Es ergibt sich erneut ein signifikanter Unterschied zwischen den Gruppen (p = 1.4 x 10-12), wobei R2 = 0.813 und R adj2 = 0.812. Die Modellanpassung hat sich durch die Transformation demnach verbessert. Die Darstellungen der Residuen in Abbildung 3 zeigen außerdem, dass sich die Heteroskedastizität deutlich verringert hat. Auch die Abweichungen von der Normalverteilung haben sich deutlich reduziert, wie in Abbildung 4 zu sehen ist.
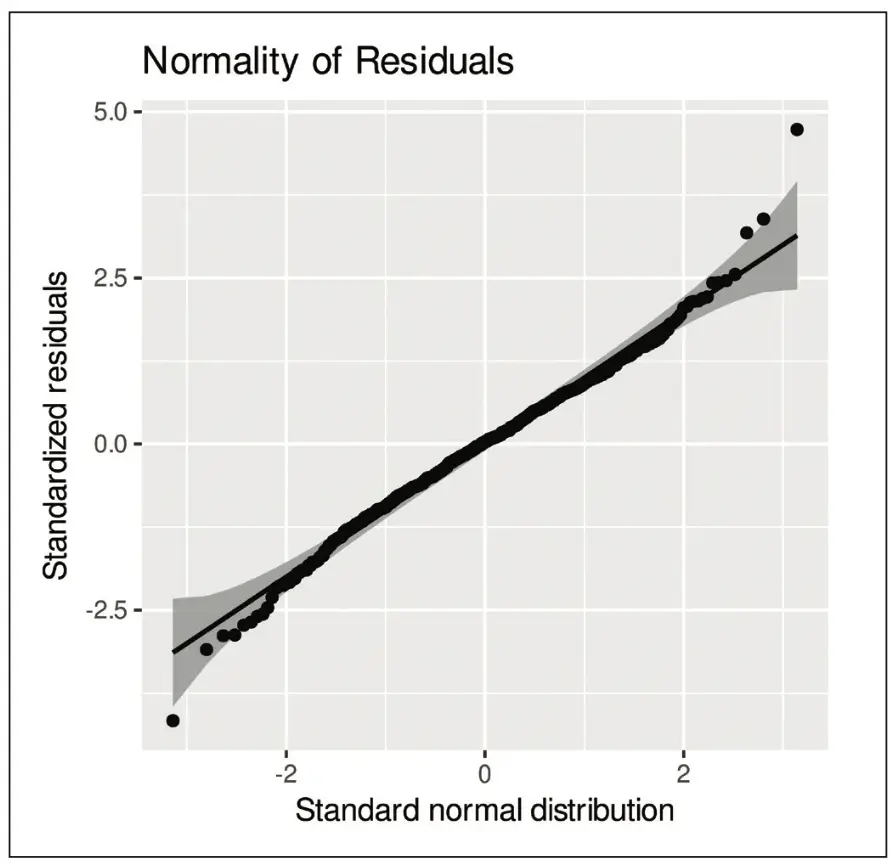
Wir gehen daher davon aus, dass die Voraussetzungen (0)–(4) nach der Transformation zumindest näherungsweise erfüllt sind und wir die Ergebnisse der linearen Regressionsanalyse für den Gruppenvergleich heranziehen können. Da wir es mit drei Gruppen zu tun haben, führen wir zusätzlich Post-hoc-Tests durch, um die Unterschiede zwischen den Gruppen genauer zu untersuchen. Wir verwenden hierfür das Paket emmeans [22]. Wir erhalten signifikante Unterschiede bei allen drei paarweisen Vergleichen (Nitroprussid vs. Nitroglycerin: p = 0.0001, Nitroprussid vs. ohne Intervention: p < 0.0001, Nitroglycerin vs. ohne Intervention: p = 0.004).
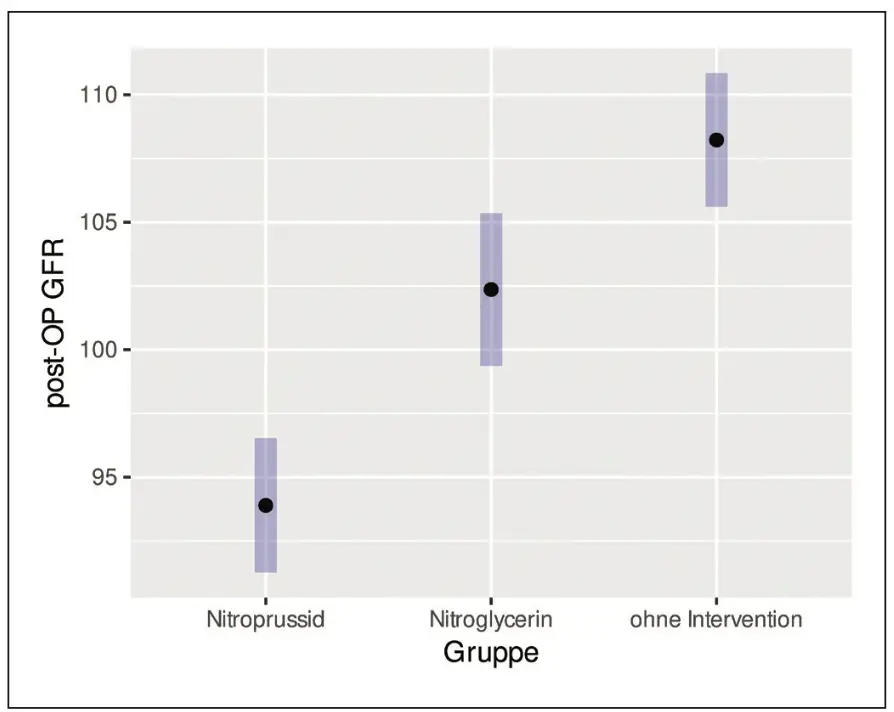
Abbildung 5 zeigt die geschätzten sogenannten marginalen Mittelwerte der post-OP GFR-Werte, die aus den Ergebnissen der ANCOVA berechnet wurden, und die zugehörigen 95 %-Konfidenzintervalle. Wir sehen, dass die post-OP GFR- Werte von der Nitroprussid-Gruppe über die Nitroglycerin-Gruppe zur Gruppe ohne Intervention signifikant ansteigen. Im Fall der 1-Weg ANOVA [2] zeigten sich nur im Vergleich der Nitroprussid-Gruppe und der Nitroglycerin-Gruppe sowie der Nitroprussid-Gruppe und der Gruppe ohne Intervention signifikante Unterschiede. Dies liegt vermutlich daran, dass die zusätzliche Adjustierung auf die prä-OP-Werte die Variabilität reduziert und so die Power der Analyse erhöht.
Wir verzichten auf komplexere Beispiele zur linearen Regression, da dies den Rahmen dieses Tutoriums deutlich sprengen würde, und empfehlen in diesem Fall auch immer einen Statistiker zu Rate zu ziehen.
Zusammenfassung
Die lineare Regression stellt ein sehr flexibles statistisches Verfahren dar, welches in vielen Fällen angewendet werden kann. Durch den Einsatz von Variablentransformationen lässt sich ihr Anwendungsbereich sogar noch weiter ausdehnen. Insbesondere die Varianz- und Kovarianzanalyse, die Spezialfälle der multiplen Regression sind, finden in vielen praktischen Studien, in denen es oft um den Vergleich von Gruppen geht, breite Anwendung. Bevor die Ergebnisse einer linearen Regressionsanalyse im Detail interpretiert werden, sollte immer eine gründliche Modelldiagnostik durchgeführt und damit die Voraussetzungen an das lineare Modell geprüft werden. Insbesondere das Bestimmtheitsmaß R2 sollte immer mit großer Vorsicht interpretiert werden, da es leicht zu manipulieren ist. Entsprechende Alternativen wie das adjustierte R2, die Mallows’ Cp Statistik, AIC- oder BIC-Kriterium sollten bei der Modellwahl zusätzlich berücksichtigt werden. Auch sollte man bei der Interpretation und Diskussion der Ergebnisse typische Phänomene beachten, die im Zusammenhang mit der linearen Regression auftreten können. In aktuellen Studien werden mehr und mehr Variablen erhoben. Wird in einem solchen Fall eine statistische Modellwahl durchgeführt, so sollte dies mit großer Sorgfalt und unter Verwendung einer internen oder externen Validierung erfolgen, damit es möglichst nicht zu verzerrten Ergebnissen kommt. Wir empfehlen außerdem bei komplexen linearen Regressionsanalysen immer einen Statistiker zu konsultieren, um methodisch falsche Vorgehensweisen und Fehlinterpretationen zu vermeiden.







